The issue I am going to talk about is relevant to anyone who uses Core Data. It is an “invisible” issue that may show up so rarely that it’s almost impossible to debug. It is only catchable by repeated automated tests.
Let’s take a look at the piece of code that has single perform(_:) which executes 2 “reads”: count and fetch.

Let’s imagine what possible pairs of count and asset may be:
- If there are no assets in store: count 0 && asset nil
- If there is 1 or more assets in store: count > 0 && asset not nil
The problem: possibility of unwanted results
There is a chance we would encounter count 0 while there is an object in the store. This is possible because a write may happen to the store after the count is read, and then the fetch will read the store at its modified state.
See test that shows the problem here https://github.com/nezhyborets/WriteBetweenTwoFetchesInSinglePerform. Run test “Repeatedly” with Maximum Repetitions 10000, it should fail at some point.
Why did I have expectations about nature of results in the first place?
Usually, when we want our Core Data to work fine in multithreaded environment, we rely on perform(_:) or performAndWait(_:) and let them do what’s needed. There is not much besides these methods when it comes to controlling resources touched by context’s threads. But turns out that these methods don’t do as much as I expected of them. Looks like database is not locked while perform is running. It is only locked for duration of fetch/save. So if you have multiple fetches in a single perform, a save from other context may write to the store between those fetches, and the fetches would return values from different states of the store.
What about main thread context?
When working with viewContext, we simply run all the fetch commands synchronously on main queue. The natural expectation is the same as with perform: 2 consecutive commands will access store at same state. The issue is also the same – same view of database is not guaranteed to those fetches by default.
TL; DR Featured solution
Set your context’s query generation to current using managedObjectContext.setQueryGenerationFrom(.current). This way, if you do multiple fetches in a single perform block, all of the will work with a single state of store, and the result will be consistent.
See more about solution below.
Making sure we are right about the cause of the problem
Let’s take a look at what happens under the hood. Let’s enable Core Data SQL debug mode by setting Launch Argument:
-com.apple.CoreData.SQLDebug 1
Count for fetch request output:
CoreData: sql: SELECT COUNT( DISTINCT t0.Z_PK) FROM ZASSET t0 WHERE t0.ZISBLURRED = ? CoreData: annotation: total count request execution time: 0.0008s for count of 0.
Regular fetch:
CoreData: sql: SELECT 0, t0.Z_PK, t0.Z_OPT, t0.ZISBLURRED FROM ZASSET t0 WHERE t0.ZISBLURRED = ? CoreData: annotation: sql connection fetch time: 0.0003s CoreData: annotation: total fetch execution time: 0.0004s for 0 rows.
Save (write) looks for inserting single object:
CoreData: sql: BEGIN EXCLUSIVE CoreData: sql: SELECT Z_MAX FROM Z_PRIMARYKEY WHERE Z_ENT = ? CoreData: sql: UPDATE OR FAIL Z_PRIMARYKEY SET Z_MAX = ? WHERE Z_ENT = ? AND Z_MAX = ? CoreData: sql: COMMIT CoreData: sql: BEGIN EXCLUSIVE CoreData: sql: INSERT INTO ZASSET(Z_PK, Z_ENT, Z_OPT, ZISBLURRED) VALUES(?, ?, ?, ?) CoreData: sql: COMMIT CoreData: sql: pragma page_count CoreData: annotation: sql execution time: 0.0001s CoreData: sql: pragma freelist_count CoreData: annotation: sql execution time: 0.0001s
Looks like such a simple write looks simple in SQL, too. Just 3 steps: begin exclusive, insert and commit. I am no expert in SQL, but quick look at SQLite doc led to conclusion that COMMIT is the statement that is interesting for us, because “read transactions” don’t see changes until “write transactions” end.
Diff of expected vs “broken” test result
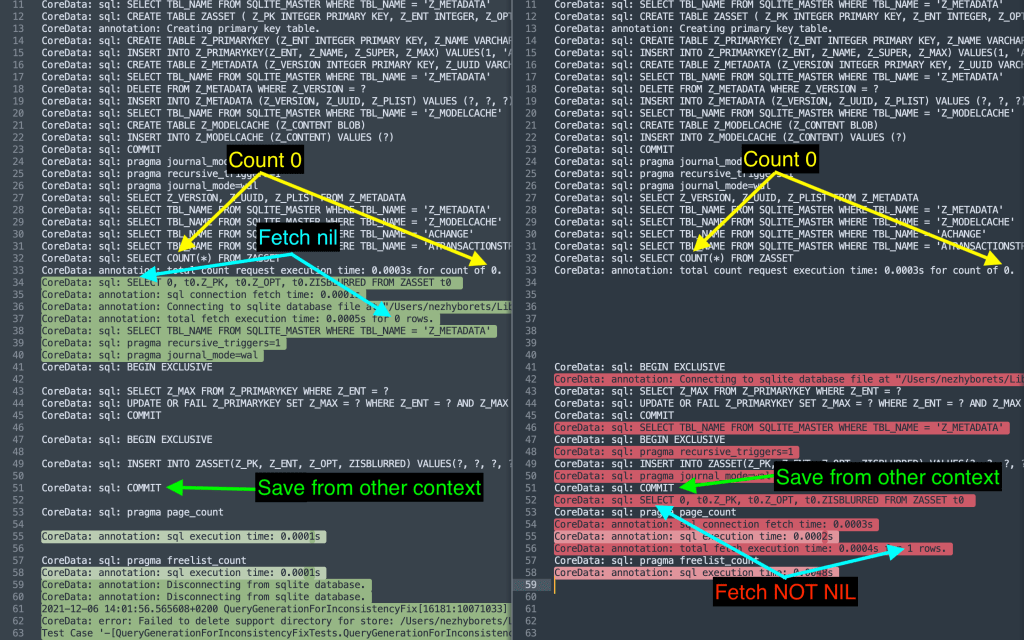
By looking at this diff it’s pretty clear that database is not “locked” for multiple consecutive reads, so a write happens between them.
There is a relevant comment in NSManagedObjectContext fetch(_:) doc that may explain why such a situation doesn’t happen too often:
Objects that have been realized (populated, faults fired, “read from”, and so on) as well as pending updated, inserted, or deleted, are never changed by a fetch operation without developer intervention. If you fetch some objects, work with them, and then execute a new fetch that includes a superset of those objects, you do not get new instances or update data for the existing objects—you get the existing objects with their current in-memory state.
https://developer.apple.com/documentation/coredata/nsmanagedobjectcontext/1506672-fetch
So, on NSManagedObjectContext level, there is some mechanism that kinda makes consecutive fetches return “same view” values. But in our case we have two “reads” that are different in their kind, so there is no in-memory value for second fetch, thus both of them go directly to store at its current-at-the-time-of-call state, without utilizing contexts caching mechanism.
The fix: Query Generations
We won’t consider “one fetch per perform” kinds of solution, because it’s easily discardable when given a second thought.
I believe the only way is to use Query Generations. It’s actually Core Datas relevantly new functionality. I don’t know how people handled the problem before.
Basically what it does is “pins” context to the specified generation of the store. This way the “view” of a database won’t change unless pin is explicitly moved to a different generation. Sounds like just what we need.
It is also easy to use. If you have basic Core Data setup with default stack, where all of your contexts automatically merge from parent, you can actually just set all of your contexts query generation tokens to .current and that’s it, no need to update it manually.

There is no need to reset token before each perform because it is automatically updated when these methods called:
setQueryGenerationFrom(_:)
https://developer.apple.com/documentation/coredata/accessing_data_when_the_store_changes
save()
mergeChanges(fromContextDidSave:)
mergeChanges(fromRemoteContextSave:into:)
reset()
Automated testing note: Query Generations don’t work with /dev/null way to reset Core Data, so you will have to use a different way to clear state, e.g. destroy stores.
Final thoughts
I kinda think that .current generation should be the default behavior for all contexts, so that we can rely on the state of the store anywhere we do fetches. Maybe there is some legacy that prevents this change, or maybe I don’t see something and this functionality is not so universal.
Initial questions that had arisen before I found out what was happening
This may be helpful for people trying to google the problem.
- Merging from parent context (store) to the background context has some synchronization issues? Actually not the case at least because we rely on merging only as a trigger for performing fetches.
- Writes to store are incremental? As there are no crashes in our tests, looks like there is at least some locking implemented for writing/reading the store. But what if context’s
save()end’s up in a write that happens in multiple stages? This way our “read” could’ve get in the middle of them, and get partially written result.
